クラスフィールド (クラス変数)
今まで、クラスはいくつかのメソッド (今までに習ったメソッドをクラスメソッドという) からなり、メソッドの中では変数の宣言をすることが出来て、その変数はそのメソッドの中だけで使えるものであった。さらに、そのクラスのすべてのメソッドで使える変数を宣言することが出来る。そのような変数は クラスフィールド (クラス変数) と呼ばれる。今のところ、クラスは一般に次のような構成になる。
public class クラス名{ クラスフィールドの宣言1 クラスフィールドの宣言2 …… クラスフィールドの宣言n クラスメソッド1 クラスメソッド2 …… クラスメソッドm }
例えば次のような例が挙げられる。
public class ClassFields {
static int hoge;
static int foo;
static int bar;
public static void main(String[] args) {
// ...
}
public static int f(int x) {
// ...
}
}
宣言
メソッドの中で宣言 (定義ともいう) されている変数 (ローカル変数と呼ぶ) は、それを宣言したブロックの内部でのみ有効。(ブロックとはプログラムの中で{…}で示される範囲を言う。ブロックは幾重にもネスティング(入れ子の形になる)されることがある。あるブロックで定義された変数は、その内部のブロックに同じ名前の定義がない限りこの内部で有効。同じ名前が内部にあるとその内部では外側の名前は使えない。)
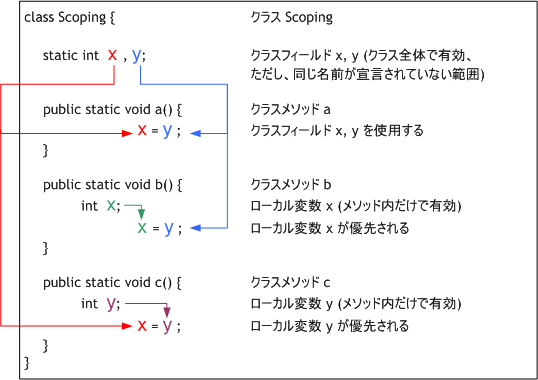
ローカル変数は自動変数である。自動変数は、それを定義しているブロックを実行し始めたとき用意され(メモリ上にその箱が作られ)、ブロックを終了したとき消失する。
クラスフィールドの宣言にはstaticとつける。例えば、xを整数型のクラスフィールドとするときは、static int xと書く。クラスフィールドはローカル変数と違って、消失することは無い。最後に書き込んだ値を参照することができる。
public class Count {
static int count;
public static void main(String[] args) {
count = 0;
countUp();
countUp();
countUp();
countDown();
countDown();
countDown();
}
public static void countUp() {
count++;
System.out.println("1増やしたカウンタの値は" + count);
}
public static void countDown() {
count--;
System.out.println("1減らしたカウンタの値は" + count);
}
}
1増やしたカウンタの値は1 1増やしたカウンタの値は2 1増やしたカウンタの値は3 1減らしたカウンタの値は2 1減らしたカウンタの値は1 1減らしたカウンタの値は0
再帰関数
Nの階乗N!は次のように定義することが出来る。
N! = 1 N = 0 のとき N! = N * (N-1)! それ以外のとき
この定義では、左辺に定義されるものがあり、右辺でそれを定義しているが、今定義しようとしている!を右辺で使っている。このような定義は再帰的(recursive)な定義と呼ばれる。
この定義によれば、3! は 3 * (3-1)! = 3 * 2! として求められ、その 2! は再び定義を使って 2 * (2-1)! = 2 * 1! として求められ、その 1! は 1 * (1-1)! = 1 * 0! として求められる。この再帰的定義の形をそのままメソッドの形にすると次のようになる。(ここでは、Nの階乗 N! のメソッドの名前を factorial とする。そうすると先ほどの定義は
factorial(N) = 1 N = 0 のとき factorial(N) = N * factorial(N-1) それ以外のとき
となる)。これをそのままプログラムにすると次のようになる。
public static int factorial(int n) {
// factorial(N) = 1 (N = 0 のとき)
if (n == 0) {
return 1;
}
// factorial(n) = n * factorial(n-1) (それ以外のとき)
else {
return n * factorial(n - 1);
}
}
このメソッドを、たとえば
System.out.println(factorial(3));
で呼び出すと、n の値を 3 としてメソッド factorial が実行される。
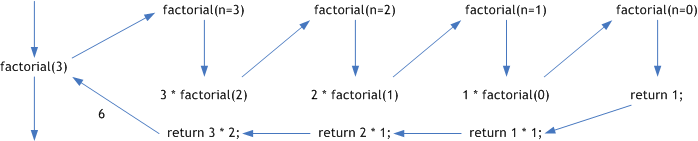
その中の return 文の中の式の計算を実行している途中で、factorial(2) が呼び出される(factorial(3)の実行は中断される)。
今度は n の値を 2 として factorial が実行される。その途中でfactorial(1)が呼び出される。
さらにその途中でfactorial(0)が呼び出される。factorial(0)が呼び出されると return 1 が実行されるから、戻り値を1としてfactorial(0)の呼び出しの直後に戻る。その呼び出しはfactorial(1)でreturn文を実行している途中の呼び出しであったから、それを再開して1*factorial(0)=1が計算されて、その値1を戻り値としてfactorial(1)の呼び出しの直後に戻る。
その結果 factorial(2) の実行が再開され 2 * factorial(1) = 2 が計算されて、その値 2 を戻り値として factorial(2) の呼び出しの直後に戻る。
それでfactorial(3)の実行が再開されて、3 * factorial(2) = 6 が計算されて、その値 6 が出力される。このように、あるメソッドの実行の途中で再びそのメソッドが呼び出されるようなメソッドは再帰的メソッドと呼ばれる。
複雑な問題は、それを、簡単な問題と元の複雑な問題を少し簡単にしたものの組み合わせであらわすと簡単に解ける場合がある。上記の階乗の計算は、N! は N (簡単な問題)と (N-1)! (元の複雑な問題を少し簡単にしたもの)を掛ける (組み合わせ) ことで得られる。このような方法を Divide and Conquer (分割し統治せよ) という。
行きがけの処理と帰りがけの処理
再帰的にメソッドを呼び出す場合、自分自身を呼び出すタイミングによって処理の流れを大きく変えることができる。下記の例は課題0804(PrimeFactors)を再帰的にメソッドを呼び出す形に書き換えたものである。
package j1.lesson09;
public class PrimeFactorsRecursive {
public static void main(String[] args) {
System.out.print(" printLeft(210):");
printLeft(210);
System.out.println();
System.out.print("printRight(210):");
printRight(210);
System.out.println();
}
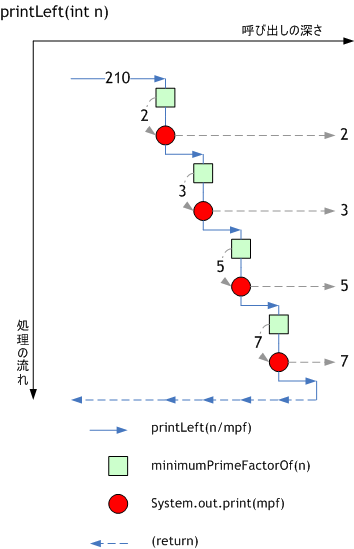
// 行きがけに表示
public static void printLeft(int n) {
if (n == 1) {
return;
}
int mpf = minimumPrimeFactorOf(n);
// 先頭で表示
System.out.print(mpf + " ");
// 末尾で再帰的呼び出し
printLeft(n / mpf);
}
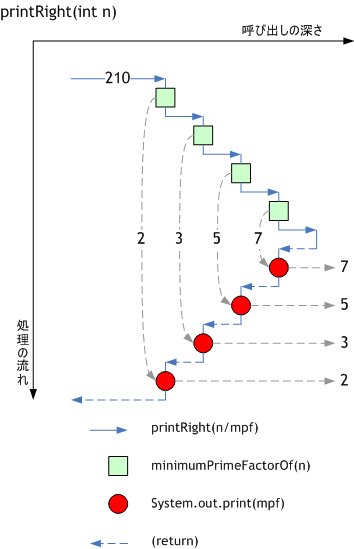
// 帰りがけに表示
public static void printRight(int n) {
if (n == 1) {
return;
}
int mpf = minimumPrimeFactorOf(n);
// 先頭で再帰的呼び出し
printRight(n / mpf);
// 末尾で表示
System.out.print(mpf + " ");
}
public static int minimumPrimeFactorOf(int n) {
if (n == 1) {
return 1;
}
else {
for (int i = 2; i <= n / 2; i++) {
if (n % i == 0) {
return i;
}
}
return n;
}
}
}
ただし、printLeftとprintRightでは自分自身を再帰的に呼び出すタイミングが異なる。printLeftは先に表示してから自分自身を呼び出すのに対し、printRightは自分自身を呼び出してから後に表示を行っている。この差異により、結果が表示される順番が変わってくる。
printLeft(210):2 3 5 7 printRight(210):7 5 3 2
このように、再帰メソッドは呼び出すタイミングを調整するだけで、処理の流れを大きく変えることができる。同時に、呼び出すタイミングを少し間違えただけで大きく処理の流れが変わるため、細心の注意を払って設計してやる必要がある。
例にあるprintLeftとprintRightの動作を図式化すると、以下のようになる。
非再帰化
一般に、メソッドの起動は時間や計算機リソースを多く消費する。再帰メソッドはプログラムが簡潔で読みやすいものになっているが、プログラムの効率を考えた場合余り良い選択とはいえない。
そこで、性能を求められるプログラムを作成する場合は、再帰的な表現をやめて、for 文や while 文を用いて非再帰的な表現に変換してやる必要がある。
演習で行うフィボナッチ数列のプログラムなどは、非再帰化した表現を探すのは難しい。非再帰化は可能だが、手順自体をすべて見直す必要があるプログラムも多々存在する。しかし、再帰メソッドの末尾で一度だけ自己呼び出しをするような再帰メソッドは、大抵は for 文などのループ構造で簡単に表現することができる。
例えば先ほどの階乗を計算するメソッド factorial(int) は、次のように書き直すことができる。
public static int factorial(int n) {
if (n == 0) {
return 1;
}
int result = 1;
for (int i = 1; i <= n; i++) {
result *= i;
}
return result;
}